Introduction to Hadoop – HDFS and Map Reduce
In the last post, we have went through the History of Hadoop. In this blog we will understand about What is Hadoop ? What does it consists of ? and Where it is used?
[1] I/O Speed
[2] Less processing time
$ Imagine one single machine which is processing 1 TB of data. So, within some time it will process it. But what if the data is more? For example say 500TB?
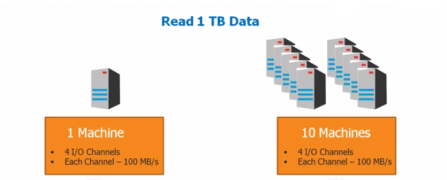
If it takes like 45 min to process 1 TB data using traditional database, then what if the data is 500TB?
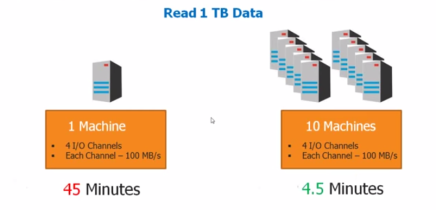
It will take lot of time and processing speed will be decreased. So, in order to overcome this problem, we are going with DFS (Distributed File System).
Hadoop Architecture mainly consists of HDFS and Map Reduce
[1] Hadoop Distributed File System
[2] Map Reduce
HDFS is used for storage and Map Reduce is used for processing the large data sets.
[2] Secondary Name node
[3] Job tracker
[2] Task tracker
[2] High throughput (Reduce the processing time)
[3] Suitable for applications with large datasets
[4] Streaming access to file system data (write once, use many times)
[5] Can be built out of commodity hardware
[2] Lots of small files
[2] It is a term used in UNIX technology
[2] Maintains and manages the blocks which are present on data nodes
[2] Responsible for sending read/write requests for the clients
[2] Secondary name node stores the data in file system Ex: HDD
In order to understand the concept of Map Reduce and how it works, we need to see about few terms used in processing of the data.
[1] Data
[2] Input Splitter
[3] Record Reader
[4] Mapper
[5] Intermediate Generator
[6] Reducer
[7] Record Writer
[8] HDFS
- The Hadoop platform consists of two key services: a reliable, distributed file system called Hadoop Distributed File System (HDFS) and the high-performance parallel data processing engine called Hadoop MapReduce.
- Hadoop was created by Doug Cutting and named after his son’s toy elephant. Vendors that provide Hadoop-based platforms include Cloudera, Hortonworks, MapR, Greenplum, IBM and Amazon.
Data Distribution
- Data distribution used in Hadoop is parallel processing and the file system used here is Distributed File System.
[1] I/O Speed
[2] Less processing time
$ Imagine one single machine which is processing 1 TB of data. So, within some time it will process it. But what if the data is more? For example say 500TB?

If it takes like 45 min to process 1 TB data using traditional database, then what if the data is 500TB?

It will take lot of time and processing speed will be decreased. So, in order to overcome this problem, we are going with DFS (Distributed File System).
High Level Architecture
[1] Hadoop Distributed File System
[2] Map Reduce
HDFS is used for storage and Map Reduce is used for processing the large data sets.
Hadoop Distributed File System
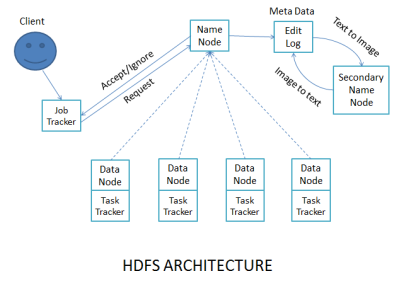
Hadoop follows Master-Slave Architecture and it has 3 Master daemon and 2 Slave daemon
- Master daemon:
[2] Secondary Name node
[3] Job tracker
- Slave daemon:
[2] Task tracker
- Why HDFS?
[2] High throughput (Reduce the processing time)
[3] Suitable for applications with large datasets
[4] Streaming access to file system data (write once, use many times)
[5] Can be built out of commodity hardware
- Design of HDFS
- Where HDFS is not used?
[2] Lots of small files
- Daemon:
[2] It is a term used in UNIX technology
- Name node:
[2] Maintains and manages the blocks which are present on data nodes
- Data node:
[2] Responsible for sending read/write requests for the clients
- Secondary Name node:
[2] Secondary name node stores the data in file system Ex: HDD
- Edit log:
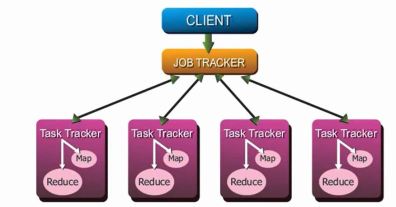
Map Reduce
It is an algorithm which is used in the Hadoop Framework for processing of the large datasets.In order to understand the concept of Map Reduce and how it works, we need to see about few terms used in processing of the data.
[1] Data
[2] Input Splitter
[3] Record Reader
[4] Mapper
[5] Intermediate Generator
[6] Reducer
[7] Record Writer
[8] HDFS
- So, we have seen about the architecture of the HDFS and now we will be discussing about the terms used in the Map Reduce Algorithm.
- As we are processing the large data sets, the first term used in this process is DATA. The input data which we want to process is nothing but the data.
- Once, we have the data in our File System nothing but the HDFS, we will be dividing/splitting into blocks.
- This blocks are also called as Chunks. The default size of this block is 64MB. But it can be expanded to 128 MB to make the processing faster.
- This means that, the input data is split into blocks based on the size we want using the Input Splitter.
- Next, we have a record reader which will map the data present into the block to the mapper. Remember the number of blocks will be equal to number of mappers. It means the HDFS will create the same no of mappers as the number of blocks or chunks. And it is done by Record Reader.
- Mapper will store the data present in the blocks. When it comes to actual definition, it is a class (specifically a Java Class) in which the initialization part is done.
- Intermediate Generator will collect all the data from the mappers and send to the reducer for the processing. Processing may include retrieving, inserting, deleting or any other kind of function or calculation.
- Sometimes, we may have duplicate or the repetitive data, in that case intermediate generator will assign by doing short shuffling nothing but check whether if there is any input data, then collects and send it to the Reducer.
- Reducer is also a Java Class which will process the data based on the code we write in the class. This will process the whole data and once the data is processed it will send to the File System nothing but the HDFS. This data is sent to HDFS using Record Writer.
- So, what HDFS is?
- HDFS is Hadoop Distributed File System which we discussed above, and it just stores the data. The Processing part of the data is done by Map Reduce.
- Finally we can say that, HDFS and Map Reduce collectively make Hadoop for the storing and processing of data.
Comments
Post a Comment